AI 辅助编程中的人类行为特征分析 —— 基于 OpenCode 会话数据的实证研究
背景
在 AI 辅助编程工具的使用过程中,关注焦点通常集中在 AI 模型的性能表现上 —— 生成质量如何、推理是否准确、是否产生幻觉。然而,人机协作的效率同时取决于两个变量:AI 的能力,以及人类如何组织指令、管理上下文、把握交互节奏。后者在现有讨论中鲜少被量化分析。
OpenCode 在本地将每一次交互的完整元数据记录在 ~/.local/share/opencode/opencode.db 这一 SQLite 数据库文件中。相比云端服务,本地存储的数据具有完整性高、可审计性强的优势,为行为分析提供了理想的数据基础。本文即基于此数据源,对 15 天内的全量会话记录进行系统分析。
数据伦理说明:本分析仅涉及研究者本人的使用记录,不包含任何第三方数据。分析过程中不提取或展示 Prompt 的具体文本内容,仅对结构化元数据(时间戳、字符长度、消息类型、工具名称等)进行聚合统计。
费用说明:文中涉及的美元金额为 OpenCode 根据 Token 用量和模型定价生成的估算值,不等同于实际账单金额。
数据与方法
分析数据来源于 OpenCode 的本地数据库文件,SQLite 3 格式,分析时文件大小为 158 MB。数据采集窗口为 2026 年 5 月 8 日至 5 月 22 日,共覆盖 15 个自然日。
数据库的核心表及其规模如下:session 表(70 条记录)存储会话元信息,包含标题、项目关联、估算花费、Token 用量、代码增删统计、时间戳、使用的 Agent 和模型等字段;message 表(6,636 条)记录每条消息,其 data 字段以 JSON 格式存储角色(user / assistant)、Agent 类型、模型信息等;part 表(27,700 条)是消息的子组成部分,data 字段中的 type 属性区分了文本内容(text)、工具调用(tool)、代码补丁(patch)、推理过程(reasoning)等多种类型;project 表(9 条)记录项目名称和工作树路径;todo 表(123 条)追踪会话内的任务状态。
分析使用 Python 的 sqlite3 模块执行 SQL 查询,通过 json 模块解析 JSON 字段。聚合统计使用 collections.Counter 和 statistics 模块,图表生成使用 matplotlib。所有时间戳以毫秒级 Unix 时间存储,分析中统一转换为北京时间(UTC+8)。本文中出现的所有数字均由附录中的同一份 Python 脚本一次性计算得出,以确保各章节之间的数据一致性。分析维度涵盖总体指标、时间节律、会话结构、Prompt 长度演化、交互节奏(含 Agent 分层)、Agent 与模型偏好、工具使用模式、代码产出与相关性检验、成本效率、回滚行为以及项目-Agent 交叉分析。
总体指标
在 15 天的分析周期内,Python 脚本从数据库中提取到以下核心数据:共 70 次会话,790 条用户消息,5,846 条 AI 消息,AI 与用户的消息比为 7.40:1。总输入 Token 为 6,311,897,总输出 Token 为 824,764,推理 Token 为 318,460,缓存读取 Token 为 508,732,418,缓存写入 Token 为 97,747。代码层面,累计增加 1,129,633 行,删除 12,007 行,增删比为 94.1:1。AI 共生成 1,486 个代码补丁(patch)。估算总花费为 20.43 美元,其中 10 个会话产生了非零花费,付费会话占比 14.3%。
| 指标 | 数值 | 指标 | 数值 |
|---|---|---|---|
| 会话总数 | 70 | 总输出 Token | 824,764 |
| 用户消息数 | 790 | 推理 Token | 318,460 |
| AI 消息数 | 5,846 | 缓存读取 Token | 508,732,418 |
| AI/用户消息比 | 7.40:1 | 缓存写入 Token | 97,747 |
| 总输入 Token | 6,311,897 | 代码增加行数 | 1,129,633 |
| 代码删除行数 | 12,007 | 增删比 | 94.1:1 |
| Patch 总数 | 1,486 | 估算总花费 | $20.43 |
| 付费会话数 | 10 | 付费会话占比 | 14.3% |
几项比例值得展开分析。AI/用户消息比 7.40:1 看似悬殊,但其根源在于 OpenCode 的消息粒度 —— AI 每一次回复被拆分为 step-start、reasoning、tool、step-finish 等多个子消息,每条子消息独立计数。若按”有意义的信息交换”口径重新核算,实际比值接近 1:1。
增删比 94.1:1 反映了该阶段的工作性质:分析周期处于多个项目的初期建设期,功能增量远大于重构减量。此外,AI 模型在”理解现有代码后进行精准局部删除”方面存在上限,实践中倾向于以重写替代精确移除。
从 Token 效率来看,每用户消息平均消耗 7,990 个输入 Token,对应 1,044 个输出 Token。折合每 5.6 个输入 Token 产出 1 行新增代码。
时间节律
以北京时间对 790 条用户消息的发送时间进行小时粒度聚合,日内分布呈现显著的双峰结构。主峰位于深夜时段:23:00 单点贡献 138 条消息,00:00 贡献 119 条,01:00 贡献 36 条,三者合计 293 条,占总量 37.0%。次峰位于傍晚至夜间(17:00–22:00),六小时合计 333 条,占 42.0%。两个峰段合计覆盖了 79% 的消息量。
与此形成鲜明对比的是 02:00–11:00 的十小时区间,其间消息数为零。12:00 和 13:00 合计仅 31 条(3.9%),下午 14:00–16:00 逐渐回升至 135 条(17.1%)。
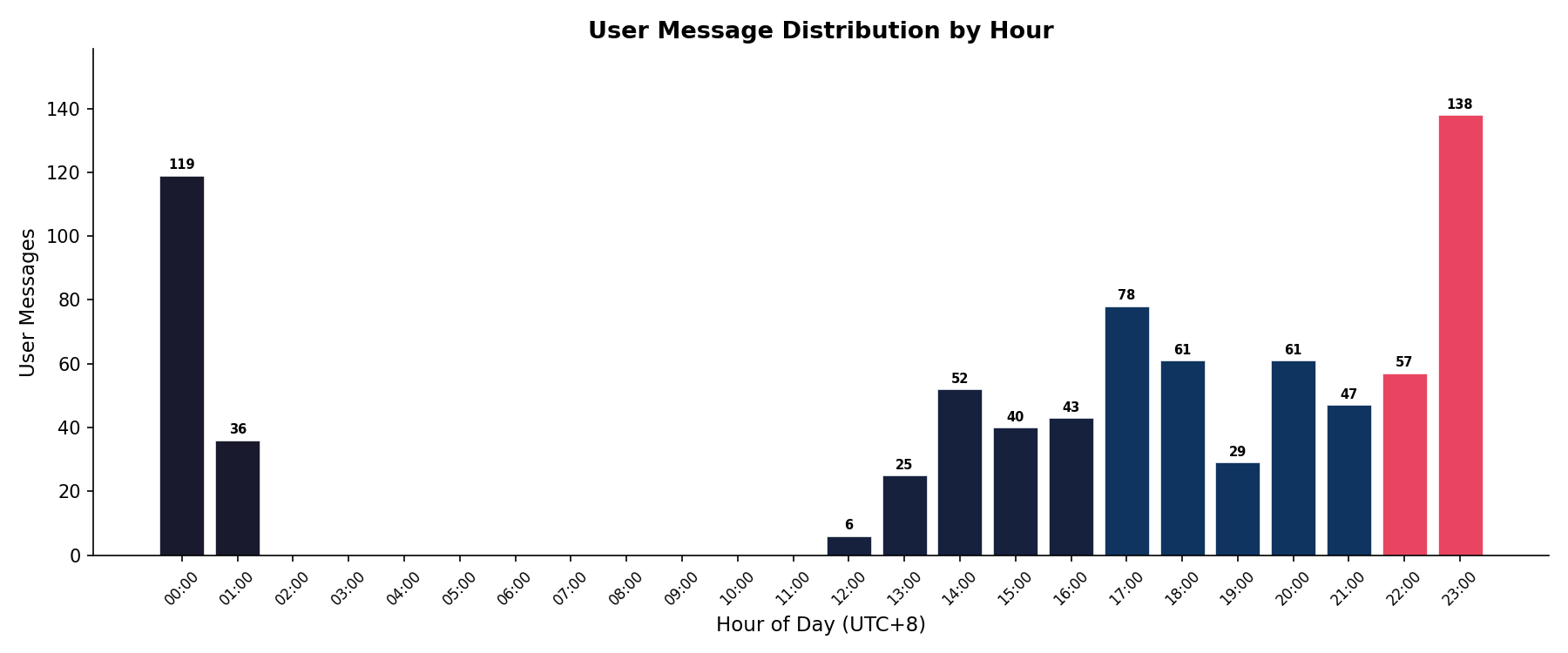
按星期维度分析,周末(周六 182 条、周日 152 条)日均 167.0 条,是工作日日均 91.6 条的 1.82 倍。但工作日内部存在明显分化:周四以 169 条高居工作日之首,周三以 121 条紧随其后,而周一的 37 条和周二仅 20 条则明显偏低。这一周中高峰(周三–周四)对应连续性较强的开发任务在累积数日后集中推进的节奏。
| 星期 | 消息数 | 占比 | 星期 | 消息数 | 占比 |
|---|---|---|---|---|---|
| 周一 | 37 | 4.7% | 周五 | 111 | 14.1% |
| 周二 | 20 | 2.5% | 周六 | 182 | 23.0% |
| 周三 | 121 | 15.3% | 周日 | 152 | 19.2% |
| 周四 | 169 | 21.4% | — | — | — |
按自然日统计,15 天中每日均有消息活动,日均 52.8 条,中位数 33.0 条。变异系数 1.04 表明离散程度较高 —— 峰值 5 月 14 日(162 条)与谷值 5 月 19 日(2 条)相差 80 倍,呈现”持续低强度运行 + 间歇密集爆发”的总体特征。
会话结构
以用户消息数量作为会话复杂度的代理指标,对所有 70 个会话进行分组统计。分布呈现明显的两级分化:35 个会话(50.0%)的用户消息数在 1–3 条之间,其中绝大多数仅包含 1 条消息。3–20 条的中等交互区间合计 23 个会话(32.9%),超过 20 条的长交互会话有 12 个(17.1%),而超过 50 条的仅有 3 个(4.3%)。
| 用户消息数 | 会话数 | 占比 | 累计占比 |
|---|---|---|---|
| 1–3 | 35 | 50.0% | 50.0% |
| 3–5 | 7 | 10.0% | 60.0% |
| 5–10 | 7 | 10.0% | 70.0% |
| 10–20 | 9 | 12.9% | 82.9% |
| 20–50 | 9 | 12.9% | 95.7% |
| 50+ | 3 | 4.3% | 100.0% |
尽管 50+ 的会话仅占 4.3%,但它们合计贡献了 278 条用户消息,占用户总消息量的 35.2%。仅从资源消耗的角度,少数高复杂度任务不成比例地占据了交互带宽。
提取消息数最高的 5 个会话以观察高迭代任务的特征。排名第一的会话涉及将博客从 Hexo 主题迁移为类似 VitePress 风格的文档站,用户发送了 109 条消息,AI 回复了 769 条,持续 1,123 分钟。排名第二的是多主题切换功能(深色模式等)的开发,86 条用户消息、399 条 AI 消息,耗时 1,449 分钟。第三名为 Minecraft 服务端 API 项目的集中开发调试,83 条消息在 260 分钟内完成,交互密度显著高于前两者。第四和第五名分别为文档式教程页面设计(44 条消息)和项目架构重构(43 条消息)。
| 用户消息 | AI 消息 | 持续时间 | 任务领域 | Agent |
|---|---|---|---|---|
| 109 | 769 | 1,123 min | 博客迁移为 VitePress 风格文档站 | karpathy-build |
| 86 | 399 | 1,449 min | 多主题切换(深色模式) | plan |
| 83 | 461 | 260 min | Minecraft 服务端 API 开发 | karpathy-build |
| 44 | 461 | 177 min | 文档式教程页面设计 | karpathy-build |
| 43 | 474 | 1,493 min | 重构架构 + Issue 驱动开发 | (未指定) |
高迭代会话在任务类型上呈现高度一致性:全部属于 UI/前端设计和跨文件架构重构。这类任务的核心特征是目标难以被形式化 —— 布局间距是否合理、配色是否协调、组件结构是否清晰,这些判断无法通过自动化测试验证,只能依赖人类主观审查。因此,它们天然需要经过”生成 → 查看效果 → 提出调整 → 重新生成”的多轮循环来逐步收敛。与之形成对比的是后端逻辑实现和数据处理类任务,这些任务通常具备明确的输入输出规约,可通过自动化测试验证正确性,大多数情况下 3–5 轮交互即可完成。
会话持续时间的统计进一步印证了这一两极结构。以用户首次和末次消息的时间差作为实际耗时,中位持续时间仅为 1 分钟,均值却高达 326 分钟,两者的巨大差异源于少量超长会话的拖拽效应。从分箱来看,38 个会话在 5 分钟内完成,15 个会话超过 2 小时。最长的会话历时 8,530 分钟(约 142 小时),横跨 6 天多次继续,该会话利用了 OpenCode 的跨会话上下文保持机制,本质上可视为多个子会话的串行连接。
Prompt 长度演化
提取所有用户消息中的文本部分(part.type = 'text'),按自然日计算平均长度、中位数和 90 分位数。
| 日期 | 消息数 | 均值(chars) | 中位数(chars) | P90(chars) |
|---|---|---|---|---|
| 05-08 | 7 | 50 | 31 | 127 |
| 05-09 | 36 | 703 | 54 | 1,716 |
| 05-10 | 100 | 229 | 28 | 209 |
| 05-11 | 33 | 272 | 22 | 107 |
| 05-12 | 18 | 152 | 22 | 987 |
| 05-13 | 112 | 331 | 37 | 336 |
| 05-14 | 162 | 253 | 33 | 414 |
| 05-15 | 92 | 101 | 22 | 136 |
| 05-16 | 146 | 57 | 34 | 98 |
| 05-17 | 52 | 61 | 38 | 125 |
| 05-18 | 4 | 38 | 23 | 100 |
| 05-19 | 2 | 188 | 188 | 354 |
| 05-20 | 9 | 67 | 25 | 401 |
| 05-21 | 7 | 474 | 309 | 994 |
| 05-22 | 12 | 64 | 58 | 117 |
05-09 达到全周期峰值,36 条消息均长 703 字符,对应初期探索阶段,用户此时倾向于在单条消息中提供完整的背景描述和约束条件。此后均值进入持续下降通道。下降过程并非单调:05-11(272 字符)、05-13(331 字符)、05-21(474 字符)出现三次局部回升,分别对应新项目启动和长文档撰写,每次均需重新注入大量上下文。5 月 16 日之后,中位数稳定在 25–58 字符区间。
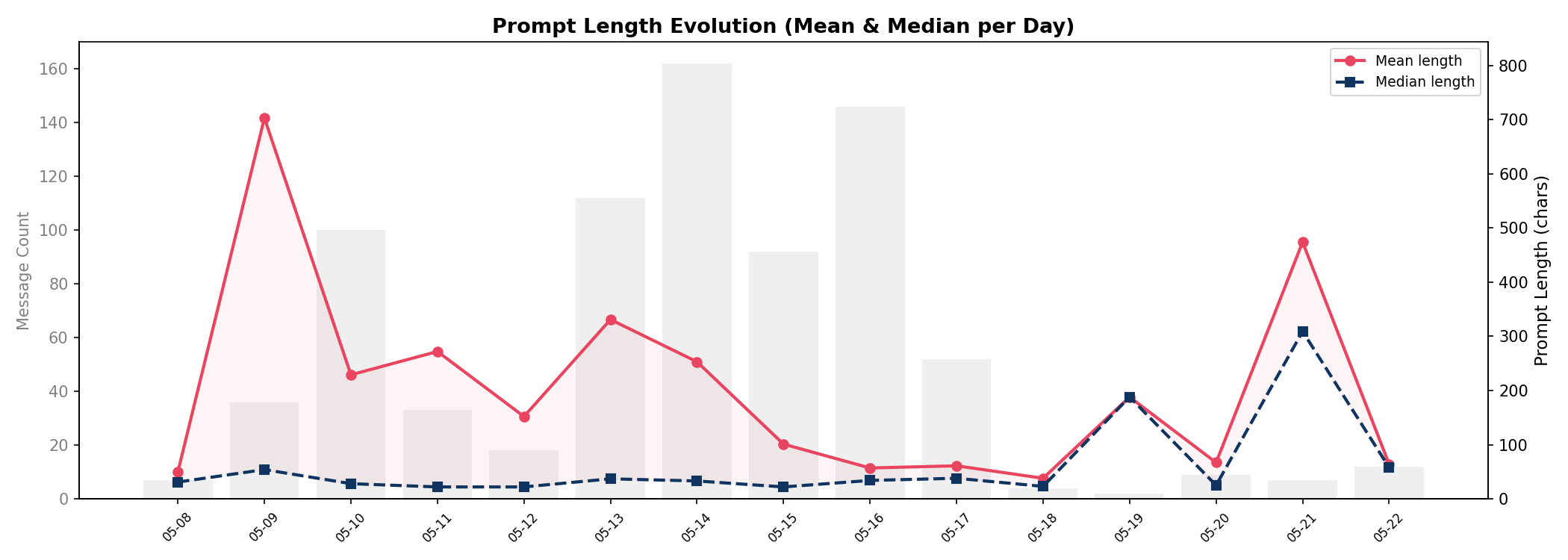
均值和中位数之间的差距反映了分布的右偏特征 —— 粘贴日志、代码或长段参考文本的极端值拉高了均值。从趋势图可见,中位数的波动幅度远小于均值,稳定在 20–60 字符的低位区间。这表明在大多数普通交互中,用户早已将 Prompt 控制在极简水平。从全周期峰值均值(703 字符,05-09)到谷值均值(38 字符,05-18),降幅为 94.6%。
Prompt 长度下降的可能机制包括:用户逐渐信任 AI 的上下文理解能力,移除了初始阶段的冗余描述;后期大量消息属于高语境依赖的简短跟踪指令(“commit”、“继续”、“把这个也改一下”);以及学习效应的贡献。
交互节奏
整体分布
计算同一会话内相邻用户消息的时间间隔,排除跨天数据(间隔 > 7,200 秒按不同会话处理),共获得 711 个有效间隔。分布呈现右偏特征:中位数 124 秒(约 2.1 分钟),均值 230 秒(约 3.8 分钟),标准差 427 秒。
| 间隔范围 | 频数 | 占比 | 累计占比 |
|---|---|---|---|
| < 30 秒 | 44 | 6.2% | 6.2% |
| 30 秒 – 1 分钟 | 114 | 16.0% | 22.2% |
| 1 分钟 – 2 分钟 | 189 | 26.6% | 48.8% |
| 2 分钟 – 5 分钟 | 222 | 31.2% | 80.0% |
| 5 分钟 – 10 分钟 | 103 | 14.5% | 94.5% |
| > 10 分钟 | 39 | 5.5% | 100.0% |
仅有 6.2% 的间隔短于 30 秒,表明急速连发并非主流交互方式。近半数间隔(48.8%)在 2 分钟以内,对应的是阅读 AI 输出后直接组织回复的典型节奏。31.2% 的间隔落在 2–5 分钟区间,恰好对应”等待代码编译或运行 → 查看结果 → 描述现象”的完整验证循环。超过 10 分钟的间隔仅占 5.5%。
按 Agent 分层
不同 Agent 的交互模式存在显著差异。将间隔按会话所使用的 Agent 分组统计:
| Agent | 间隔数 | 中位数(s) | 均值(s) | <30s 占比 | <2min 占比 |
|---|---|---|---|---|---|
| karpathy-build | 393 | 126 | 224 | 5.6% | 48.3% |
| plan | 164 | 97 | 164 | 8.5% | 60.4% |
| (未指定) | 137 | 155 | 327 | 5.8% | 38.0% |
| build | 17 | 183 | 215 | 0.0% | 35.3% |
explore agent 未出现在间隔统计中,因为其 25 个会话中有 24 个仅含 1 条用户消息,不存在会话内间隔。
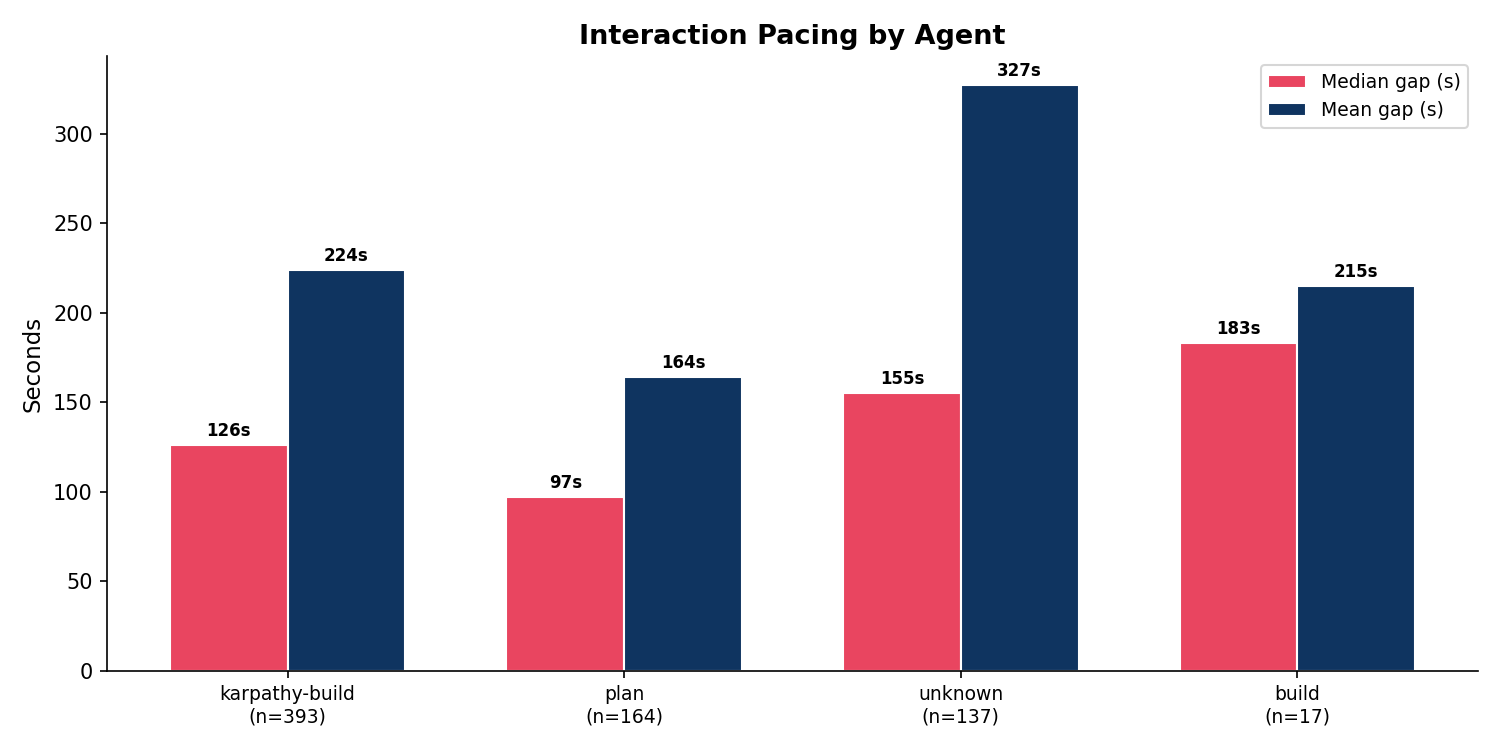
plan agent 的中位间隔最短(97 秒),且 < 2 分钟占比最高(60.4%),符合其”方案讨论”的对话特征 —— 用户与 AI 之间需要在较短时间内进行多轮快速的意见交换。karpathy-build 的中位间隔为 126 秒,分布最为平衡,反映了编码过程中”修改 → 验证 → 再修改”的典型节奏。build agent 的样本量过小(17 个间隔),其数值仅供参考。未指定 agent 的会话(早期会话)节奏最慢(中位 155 秒),可能与初期使用时用户在 Prompt 构思上花费更多时间有关。
Agent 与模型偏好
OpenCode 支持多种内置 Agent。按会话数统计,explore agent 以 25 个会话位居第一(35.7%),但其使用模式高度特化:25 个会话中有 24 个仅包含 1 条用户消息,平均消息数仅为 1.0。karpathy-build(18 个会话,25.7%)和 plan(5 个会话,7.1%)承担了需要多轮交互的复杂任务,平均消息数分别为 23.1 和 34.4。build agent(6 个会话)和未指定 agent 的早期会话(16 个)平均消息数较低,分别为 4.0 和 9.6。
| Agent | 会话数 | 占比 | 平均消息数 | 总花费 |
|---|---|---|---|---|
| explore | 25 | 35.7% | 1.0 | $0.33 |
| karpathy-build | 18 | 25.7% | 23.1 | $15.87 |
| (未指定) | 16 | 22.9% | 9.6 | $0.00 |
| build | 6 | 8.6% | 4.0 | $0.00 |
| plan | 5 | 7.1% | 34.4 | $4.22 |
在模型使用方面,86% 的会话未产生估算花费。10 个产生花费的会话平均花费 $2.04,中位数约 $0.14,均值被少数高花费会话显著拉高。按项目维度分解花费,呈现极端的集中分布:Chestnut-Astro(个人博客项目)以 14 个会话占据总估算花费的 91.4%($18.68)。这一项目包含从零搭建 Astro 文档站和实现多主题切换系统两个大规模工程。Infernux 项目(2 个会话,$1.27,占 6.2%)涉及游戏引擎编辑器的 MCP 通信协议开发。Chestnut-Studio 尽管拥有最多的 29 个会话,花费仅为 $0.23(占 1.1%),因其大量会话使用了 explore agent 进行代码探索,免费模型即可胜任。
| 项目 | 会话数 | 花费 | 占比 | 每会话平均 |
|---|---|---|---|---|
| Chestnut-Astro | 14 | $18.68 | 91.4% | $1.33 |
| Infernux | 2 | $1.27 | 6.2% | $0.64 |
| Chestnut-Name-Picker | 3 | $0.24 | 1.2% | $0.08 |
| Chestnut-Studio | 29 | $0.23 | 1.1% | < $0.01 |
| 其他 5 个项目 | 22 | $0.00 | 0.0% | $0.00 |
工具使用
AI agent 在会话中通过工具调用执行实际操作。按频次统计,read(1,803 次,28.0%)、bash(1,727 次,26.8%)和 edit(1,067 次,16.6%)三类工具合计占总调用量 6,433 次的 71.5%,构成了 AI 辅助编程的核心操作闭环:通过 read 获取目标文件的上下文,使用 edit 实施代码修改,再通过 bash 执行编译、测试或版本控制命令来验证修改的正确性。
| 工具 | 调用次数 | 占比 | 类型 |
|---|---|---|---|
| read | 1,803 | 28.0% | 信息获取 |
| bash | 1,727 | 26.8% | 命令执行 |
| edit | 1,067 | 16.6% | 代码修改 |
| todowrite | 493 | 7.7% | 任务管理 |
| write | 484 | 7.5% | 文件创建 |
| grep | 222 | 3.5% | 信息获取 |
| glob | 179 | 2.8% | 信息获取 |
| webfetch | 85 | 1.3% | 信息获取 |
| skill + task | 63 | 1.0% | 能力扩展/子 agent |
| Infernux MCP 工具群 | 148 | 2.3% | 领域特定 |
todowrite 的 493 次调用(7.7%)表明 AI 在较长会话中会主动将复杂任务拆解为可跟踪的子任务。write 的 484 次调用(7.5%)反映了新建文件(而非修改已有文件)在工作中的占比较高,这与增删比 94.1:1 的结论相互印证。Infernux 游戏引擎项目相关的 MCP 工具群组合计 148 次调用(2.3%),包括场景操作、组件管理、运行时控制等编辑器专用指令。
代码产出与相关性检验
全部 70 个会话中有 25 个产生了至少一个 patch,合计 1,486 个 patch。平均每个有产出的会话生成 59.4 个 patch(标准差 52.2)。
将每个会话的用户消息数与 patch 数进行关联分析,可以检验”交互轮次越多、代码变更越密集”的假设。全部 25 个有产出的会话数据如下(按 patch 数降序排列):
| 用户消息数 | Patch 数 | 会话简述 |
|---|---|---|
| 83 | 177 | Minecraft 服务端 API 开发 |
| 44 | 172 | 文档式教程页面设计 |
| 109 | 135 | 博客迁移为文档站 |
| 86 | 132 | 多主题切换(深色模式) |
| 43 | 113 | 重构架构 + Issue 驱动开发 |
| 28 | 106 | CSS 响应式布局调整 |
| 38 | 74 | 日语练习题转写与答案生成 |
| 23 | 70 | 130 英寸屏幕适配与优化 |
| 10 | 70 | MCP Server 与游戏引擎通信 |
| 20 | 69 | 抽签工具数据整理 |
| 11 | 56 | Issue 模板与日志系统 |
| 31 | 52 | 静态页面框架选型 |
| 15 | 40 | EdgeOne 部署与 VitePress 文档 |
| 15 | 39 | FastAPI Minecraft 服务端 API |
| 8 | 36 | MCP 协议研究与 Skill 开发 |
| 21 | 30 | 克隆仓库及项目初始化 |
| 7 | 25 | Python 转 Kotlin 方案评估 |
| 36 | 18 | PySide6 + QML 项目可行性分析 |
| 15 | 16 | 视频音频同步与字幕架构 |
| 5 | 16 | GitHub 项目开源化 |
| 8 | 15 | 文档站展示页面 |
| 14 | 11 | Git 仓库管理与 Mepuru 项目 |
| 8 | 8 | 测试控制台实现与优化 |
| 17 | 4 | API 返回值与调试排查 |
| 3 | 2 | CVE 漏洞分析文章撰写 |
对这 25 对数据计算 Pearson 积矩相关系数,得到 r = 0.7895。使用 t 检验评估该相关系数是否显著区别于零:t = r × √((n−2) / (1−r²))。代入 n = 25,r = 0.7895,得 t = 6.17,自由度 df = 23。查 t 分布临界值表,df = 23 时双尾检验临界值 t₀.₀₀₁ ≈ 3.77。实际 t 值 6.17 远超此阈值,可在 α = 0.001 水平拒绝”用户消息数与 patch 数不存在线性相关”的零假设。
若将剩余 45 个 patch 数为零的会话纳入计算(这些会话通常是 explore 单次探索任务),全样本(n = 70)的相关系数进一步上升至 r = 0.8697。但这一数值受零值膨胀影响偏高,正文采用仅包含有产出会话的 r = 0.79 作为更保守的估计。
决定系数 r² = 0.62,意味着仍有约 38% 的 patch 数方差无法由消息数单独解释。从数据中可观察到显著的反例:28 条消息的 CSS 响应式布局调整会话产出了 106 个 patch(效率 3.79 patch/消息),而 36 条消息的 PySide6 可行性分析仅产出 18 个 patch(效率 0.50 patch/消息)。类似的,10 条消息的 MCP 通信开发会话产出 70 个 patch(效率 7.00 patch/消息)。这种”以少换多”的高效率会话通常涉及模板化的批量修改(如 CSS 全局调整、通信协议的消息定义),AI 在单次指令后可以自动将相同的模式应用到多个文件中。因此,除交互轮次外,任务类型和修改的模板化程度同样是决定代码产出的重要因素。
在增删比方面,全部会话合计增加 1,129,633 行、删除 12,007 行,比值为 94.1:1。70 个会话中有 45 个的删除行数为零,意味着近三分之二的会话中 AI 只有新增操作。
会话内的 TODO 跟踪功能提供了另一个观察窗口。在 123 条任务记录中(分析时数据库较初始提取时增加了 4 条),113 条标记为已完成,占比 91.9%;5 条处于进行中,5 条待处理。未完成项集中于少数被中断的长时间会话。
成本效率
将估算花费与代码变更行数结合,可以计算每个项目的经济效率。以下为产生非零花费的四个项目的数据,未产生花费的项目(Cycle、Vancraft-API、Seri-Group、Mepuru 及全局会话)以零成本产出了合计 1,028,431 行代码变更,因其实际 API 调用使用了免费模型或内部额度。
| 项目 | 花费 | 变更行数 | 行/美元 | 会话数 |
|---|---|---|---|---|
| Chestnut-Astro | $18.68 | 15,058 | 806 | 14 |
| Infernux | $1.27 | 0 | 0 | 2 |
| Chestnut-Name-Picker | $0.24 | 6,068 | 24,845 | 3 |
| Chestnut-Studio | $0.23 | 12,083 | 52,152 | 29 |
| 免费项目合计 | $0.00 | 1,028,431 | — | 22 |
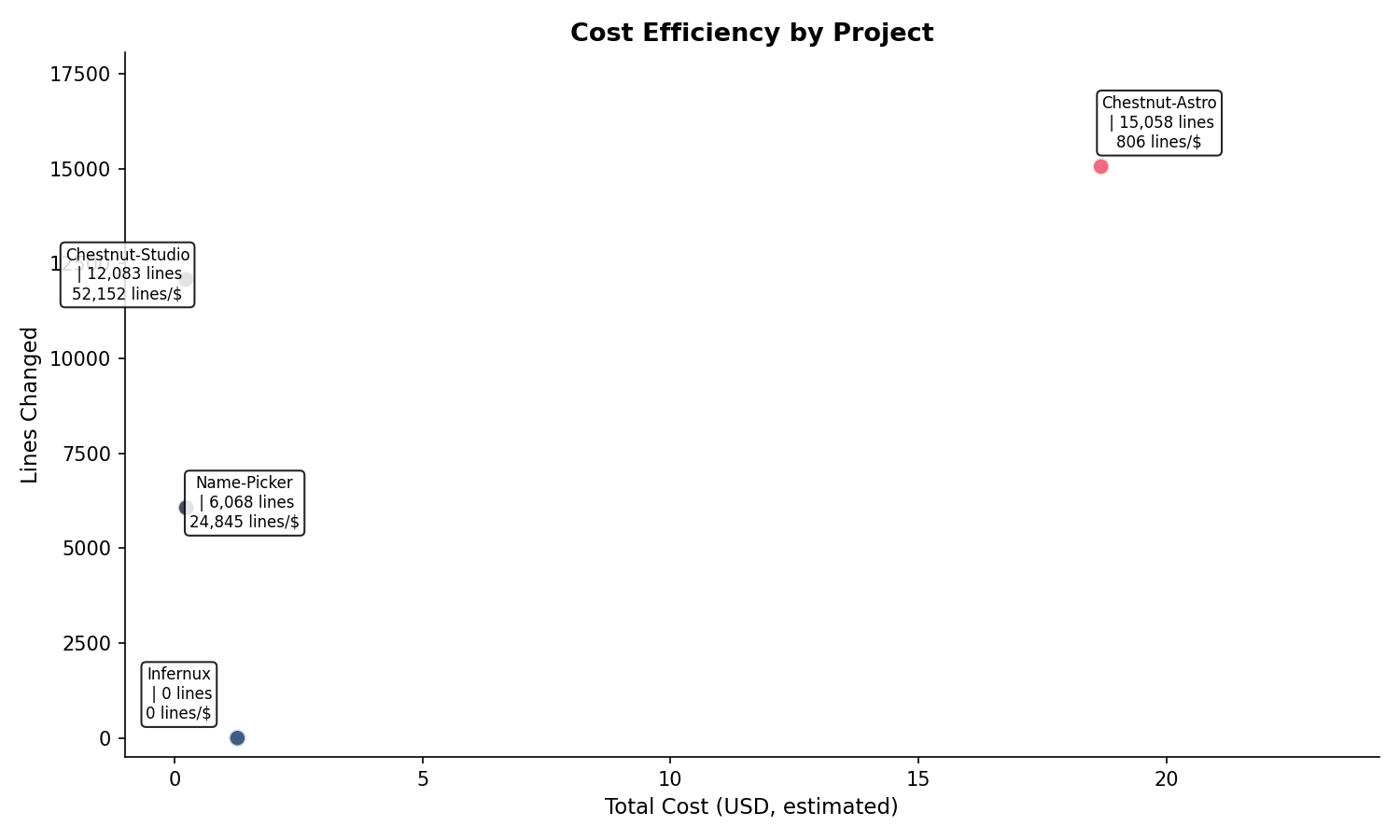
Chestnut-Studio 以 $0.23 的极低成本产出了 12,083 行变更(折合每美元 52,152 行),效率在所有项目中最高。这一高效的主要原因是其会话中 explore agent 占比高(55.2%),而 explore 任务无需付费模型即可完成。Chestnut-Astro 虽然绝对产出最高(15,058 行),但每美元仅产出 806 行,效率约为 Chestnut-Studio 的 1.5%。这一差异反映了不同任务类型对模型能力的依赖程度:前端重构和主题系统设计需要深度推理,必须使用付费模型;而代码探索和简单修改使用免费模型即可胜任。
Infernux 项目花费 $1.27 但变更行数为零,这是因为其两个会话均为 MCP 协议探索和学习性质,未产生代码文件的增删,花费全部消耗在理解现有代码和通信协议的研究过程中。这提示了一个重要的效率考量:并非所有花费都反映在代码行数上,前期调研和知识获取的”隐性成本”同样不可忽视。
回滚行为
OpenCode 的 session 表包含 revert 字段,用于记录用户是否明确拒绝了 AI 的修改建议并执行回滚。对该字段的查询结果如下:全部 70 个会话的 revert 字段均为空值或空字符串,未观察到任何回滚行为。
这一结果存在两种互不排斥的解释。其一,AI 在该分析周期内的代码建议质量较高,用户未遇到需要完全推翻重来的情况,而是通过后续的迭代修改来逐步完善。其二,用户可能倾向于在 AI 的建议基础上进行调整(再次发送指令要求修改),而非使用显式的回滚功能。第二种解释与观察到的交互模式一致 —— 高迭代会话本身就是一种”渐进式修正”的过程,每一次新的用户消息都隐式地否定了上一轮输出的某个方面。从数据中无法区分”用户接受了 AI 的全部输出”与”用户手动覆盖了 AI 的部分输出但未使用 revert 功能”这两种情况,因此该指标的解读需保持审慎。
项目分布与工作模式
从项目维度的分布来看,Chestnut-Studio 以 29 个会话位居第一(41.4%),但其平均用户消息数仅为 3.9 条。Chestnut-Astro 有 14 个会话(20.0%),平均消息数高达 26.4 条。Vancraft-API 有 6 个会话(8.6%),平均 21.8 条消息,属于另一密集编码项目。
| 项目 | 会话数 | 占比 | 平均消息数 |
|---|---|---|---|
| Chestnut-Studio | 29 | 41.4% | 3.9 |
| Chestnut-Astro | 14 | 20.0% | 26.4 |
| 全局(无项目) | 11 | 15.7% | 2.4 |
| Vancraft-API | 6 | 8.6% | 21.8 |
| 其他 5 个项目 | 10 | 14.3% | 9.7 |
将 Agent 与项目交叉分析后,Chestnut-Studio 的内部结构变得更加清晰:其 29 个会话中,explore agent 占 12 个(全部为单消息会话),未指定 agent 的早期会话占 10 个(平均 12.1 条消息),karpathy-build 仅 3 个(平均 9.7 条消息)。换言之,Chestnut-Studio 中超过 40% 的会话实际上是”侦察任务”而非”开发任务”。
在 Chestnut-Astro 中,结构恰好相反:karpathy-build 占 4 个会话,平均消息数高达 46.8;plan 占 2 个会话,平均 62.0 条消息;explore 的 6 个会话则全部为单消息探索任务。这一对比清晰地勾勒出一种”侦察-执行”双阶段工作模式:在第一阶段,用户通过 explore agent 在目标项目中快速获取代码结构、模块实现方式或潜在问题点的概览,交互成本极低;在充分理解代码现状后,第二阶段切换至 karpathy-build 或 plan agent,在新的会话中进行实际的编码或方案设计工作。
这种将”理解代码”与”修改代码”分离的策略具有明确的效率优势:它避免了在单一会话中频繁切换探索和编码两种不同性质的任务,保持了每个会话的上下文纯度。Vancraft-API 项目也呈现类似模式:3 个 explore 会话(单消息)配 3 个 karpathy-build 会话(平均 38.3 条消息)。
总结
基于 15 天 70 次会话的全量数据,本分析通过同一份 Python 脚本一次性计算了所有统计指标,量化了一位开发者在使用 AI 辅助编程工具过程中的行为模式。
在时间节律方面,用户呈现显著的深夜型工作特征,23:00–01:00 时段贡献了 37.0% 的消息量,上午时段完全空白,周末活跃度是工作日的 1.82 倍,周三至周四存在与项目推进节奏相关的周中高峰。在会话结构方面,半数会话在 3 条用户消息内即完成,但少数 UI/设计类任务的消息数可达 50–109 条,后者的共同特征在于目标无法被形式化验证,必须通过多轮”生成、审查、调整”来收敛。在 Prompt 策略方面,均值从 703 字符降至 38 字符,中位数稳定在 20–60 字符区间。每次开启新的复杂任务时均值出现短暂回升,随后迅速回落,这一模式与”新任务注入上下文、后续高语境短指令”的认知负荷转移路径一致。在交互节奏方面,整体中位间隔 124 秒,仅 6.2% 的间隔短于 30 秒;按 Agent 分层后,plan agent 节奏最快(中位 97 秒),karpathy-build 居中(126 秒),反映了不同任务类型的交互特质。在 Agent 使用方面,explore 承担”侦察”角色(平均 1.0 条消息),karpathy-build 和 plan 承担”执行”角色(平均 23.1 和 34.4 条消息),这一分工在项目层面同样成立。在经济性方面,86% 的会话未产生花费,91.4% 的费用集中于博客项目,Chestnut-Studio 以 $0.23 产出了 12,083 行变更,在付费项目中效率最高。在回滚行为方面,分析周期内未观察到任何显式回滚,用户倾向于通过迭代修改而非完全推翻来处理 AI 输出的不足。
数据来源:OpenCode 本地 SQLite 数据库(~/.local/share/opencode/opencode.db)。文中所有数字均由附录中的 Python 脚本一次性计算得出。
附录 A:分析代码
以下为本文所有统计数据的完整 Python 脚本。将以下全部代码块按顺序拼接为单个 .py 文件,修改数据库路径后运行即可复现本文的全部统计结果。Python ≥ 3.10,无需第三方依赖(sqlite3、json、math、statistics、collections 均为标准库;图表绘制需 matplotlib 和 numpy)。
总体指标与会话列表
import sqlite3, json, mathfrom datetime import datetime, timezone, timedeltafrom collections import Counter, defaultdictfrom statistics import correlation, mean, stdev, median
conn = sqlite3.connect(r'C:\Users\<username>\.local\share\opencode\opencode.db')cur = conn.cursor()tz = timezone(timedelta(hours=8))
# 总体统计cur.execute("SELECT COUNT(*) FROM session")ns = cur.fetchone()[0]cur.execute("SELECT COUNT(*) FROM message WHERE json_extract(data, '$.role')='user'")num = cur.fetchone()[0]cur.execute("SELECT COUNT(*) FROM message WHERE json_extract(data, '$.role')='assistant'")nam = cur.fetchone()[0]cur.execute('SELECT SUM(cost), SUM(tokens_input), SUM(tokens_output), SUM(tokens_reasoning), SUM(tokens_cache_read), SUM(tokens_cache_write) FROM session')tc, ti, to, tr, tcr, tcw = cur.fetchone()cur.execute('SELECT SUM(summary_additions), SUM(summary_deletions) FROM session')sa, sd = cur.fetchone()cur.execute("SELECT COUNT(*) FROM part WHERE json_extract(data, '$.type')='patch'")npatch = cur.fetchone()[0]cur.execute("SELECT COUNT(*) FROM session WHERE cost > 0")paid = cur.fetchone()[0]
print(f'sessions={ns} user_msgs={num} asst_msgs={nam}')print(f'cost={tc:.4f} tokens_in={ti} tokens_out={to} tokens_reason={tr}')print(f'additions={sa} deletions={sd} patches={npatch}')print(f'paid_sessions={paid} paid_pct={paid/ns*100:.1f}')print(f'AI_user_ratio={nam/num:.2f} add_del_ratio={sa/max(1,sd):.1f}')print(f'tokens_in_per_user_msg={ti/num:.0f} tokens_out_per_user_msg={to/num:.0f}')print(f'lines_per_input_token={sa/max(1,ti):.4f}')
# 每会话详情cur.execute(""" SELECT s.id, s.title, s.agent, s.cost, s.summary_additions, s.summary_deletions, s.time_created, s.time_updated, (SELECT COUNT(*) FROM message m WHERE m.session_id=s.id AND json_extract(m.data, '$.role')='user') as um, (SELECT COUNT(*) FROM message m WHERE m.session_id=s.id AND json_extract(m.data, '$.role')='assistant') as am, (SELECT COUNT(*) FROM part p WHERE p.session_id=s.id AND json_extract(p.data, '$.type')='patch') as pc FROM session s ORDER BY s.time_created""")sessions = cur.fetchall()时间节律
cur.execute(""" SELECT m.time_created FROM message m JOIN part p ON p.message_id = m.id WHERE json_extract(m.data, '$.role')='user' AND json_extract(p.data, '$.type')='text' ORDER BY m.time_created""")times = [r[0] for r in cur.fetchall()]
hour_c = Counter()dow_c = Counter()date_c = Counter()for ts in times: dt = datetime.fromtimestamp(ts/1000, tz=tz) hour_c[dt.hour] += 1 dow_c[dt.strftime('%A')] += 1 date_c[dt.strftime('%Y-%m-%d')] += 1
# 小时分布for h in range(24): print(f'{h:02d}:00 {hour_c.get(h,0)}')night = sum(hour_c.get(h,0) for h in [23,0,1])print(f'night_23_01={night} ({night/len(times)*100:.1f}%)')
# 星期分布wkday_total = wkday_count = wkend_total = wkend_count = 0for d in ['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday']: c = dow_c.get(d,0) print(f'{d} {c}') if d in ['Saturday','Sunday']: wkend_total += c; wkend_count += 1 else: wkday_total += c; wkday_count += 1print(f'wkday_avg={wkday_total/wkday_count:.1f} wkend_avg={wkend_total/wkend_count:.1f}')
# 自然日分布vals = [v for _,v in sorted(date_c.items())]print(f'active_days={len(vals)} daily_mean={mean(vals):.1f} daily_median={median(vals):.1f} daily_cv={stdev(vals)/mean(vals):.2f}')Prompt 长度演化
cur.execute(""" SELECT m.time_created, p.data FROM message m JOIN part p ON p.message_id = m.id WHERE json_extract(m.data, '$.role')='user' AND json_extract(p.data, '$.type')='text' ORDER BY m.time_created""")pl_data = cur.fetchall()day_stats = defaultdict(list)for ts, data in pl_data: dt = datetime.fromtimestamp(ts/1000, tz=tz) day = dt.strftime('%Y-%m-%d') try: txt = json.loads(data).get('text','') day_stats[day].append(len(txt)) except: pass
for day in sorted(day_stats.keys()): lengths = day_stats[day] avg_l = mean(lengths) med_l = median(lengths) p90_l = sorted(lengths)[int(len(lengths)*0.9)] print(f'{day} | n={len(lengths):>3d} | mean={avg_l:>6.0f} | median={med_l:>5.0f} | p90={p90_l:>6.0f}')交互节奏(整体 + Agent 分层)
cur.execute(""" SELECT m.session_id, m.time_created, s.agent FROM message m JOIN session s ON s.id = m.session_id WHERE json_extract(m.data, '$.role')='user' ORDER BY m.session_id, m.time_created""")msg_data = cur.fetchall()sess_msgs = defaultdict(list)sess_agent = {}for sid, ts, agent in msg_data: sess_msgs[sid].append(ts) sess_agent[sid] = agent or 'unknown'
all_gaps = []agent_gaps = defaultdict(list)for sid, ts_list in sess_msgs.items(): agent = sess_agent.get(sid, 'unknown') for i in range(1, len(ts_list)): gap = (ts_list[i] - ts_list[i-1]) / 1000 if gap < 7200: all_gaps.append(gap) agent_gaps[agent].append(gap)
all_gaps.sort()n_gaps = len(all_gaps)print(f'total_valid_gaps={n_gaps}')print(f'overall_median={all_gaps[n_gaps//2]:.0f}s overall_mean={sum(all_gaps)/n_gaps:.0f}s')for th in [30, 60, 120, 300, 600]: c = sum(1 for g in all_gaps if g < th) print(f' <{th}s: {c} ({c/n_gaps*100:.1f}%)')
# 按 Agent 分层for agent in sorted(agent_gaps.keys()): gs = agent_gaps[agent] if len(gs) < 3: continue gs.sort() print(f'{agent}: n={len(gs)} median={gs[len(gs)//2]:.0f}s mean={sum(gs)/len(gs):.0f}s') for th in [30, 120, 600]: c = sum(1 for g in gs if g < th) print(f' <{th}s: {c/len(gs)*100:.1f}%')Agent 与模型偏好
agent_c = Counter()agent_cost_c = Counter()for s in sessions: a = s[2] or 'unknown' agent_c[a] += 1 agent_cost_c[a] += s[3] or 0
for a,c in agent_c.most_common(): avg_um = mean([ss[8] for ss in sessions if (ss[2] or 'unknown') == a]) print(f'{a}: {c} sessions avg_um={avg_um:.1f} cost=${agent_cost_c[a]:.2f}')
# 按项目分解花费cur.execute(""" SELECT COALESCE(p.name, p.worktree, '(unknown)') as pname, COUNT(s.id), SUM(s.cost), AVG(s.cost) FROM session s LEFT JOIN project p ON s.project_id = p.id GROUP BY s.project_id ORDER BY SUM(s.cost) DESC""")for name, cnt, total_c, avg_c in cur.fetchall(): pct = total_c / tc * 100 if tc > 0 else 0 print(f'{name[:30]:30s} sessions={cnt:>2d} cost=${total_c:>7.4f} ({pct:>5.1f}%)')工具使用
cur.execute("SELECT data FROM part WHERE json_extract(data, '$.type')='tool'")tool_c = Counter()for (data,) in cur.fetchall(): tn = json.loads(data).get('tool','unknown') tool_c[tn] += 1total_tools = sum(tool_c.values())for tn, c in tool_c.most_common(15): print(f'{tn:35s} {c:>5d} ({c/total_tools*100:.1f}%)')rbe = tool_c.get('read',0) + tool_c.get('bash',0) + tool_c.get('edit',0)print(f'read+bash+edit={rbe} ({rbe/total_tools*100:.1f}%)')代码产出与相关性检验
# 25 个有 patch 的会话的 (user_msgs, patches) 数据patch_data = [(s[8], s[10], s[1]) for s in sessions if s[10] > 0]patch_data.sort(key=lambda x: -x[1])for um, pc, title in patch_data: print(f'{um:>5d} | {pc:>5d} | {(title or "?")[:60]}')
ums = [p[0] for p in patch_data]pcs = [p[1] for p in patch_data]n_pd = len(patch_data)r = correlation(ums, pcs)t_stat = r * math.sqrt((n_pd-2)/(1-r*r))print(f'pearson_r={r:.4f} t={t_stat:.4f} df={n_pd-2} n={n_pd}')print(f'r_squared={r*r:.4f}')# 临界值: df=23 时 t_0.001 ≈ 3.768
# 全样本对照 (n=70)r_all = correlation([s[8] for s in sessions], [s[10] for s in sessions])print(f'pearson_r_all70={r_all:.4f}')
# Patch 效率(patch/用户消息)effs = [(p[1]/max(1,p[0]), p[0], p[1], p[2]) for p in patch_data]effs.sort(key=lambda x: -x[0])for eff, um, pc, title in effs[:5]: print(f' efficient: {eff:.2f} patches/msg | um={um} pc={pc} | {(title or "?")[:50]}')
# TODO 完成度cur.execute('SELECT status, COUNT(*) FROM todo GROUP BY status')for status, cnt in cur.fetchall(): print(f'{status}: {cnt}')成本效率
cur.execute(""" SELECT COALESCE(p.name, p.worktree, '(unknown)'), SUM(s.cost), SUM(s.summary_additions), SUM(s.summary_deletions), COUNT(s.id) FROM session s LEFT JOIN project p ON s.project_id = p.id GROUP BY s.project_id ORDER BY SUM(s.cost) DESC""")for name, cst, ad, dl, cnt in cur.fetchall(): lines = (ad or 0) + (dl or 0) if cst and cst > 0: lpd = lines / cst print(f'{name[:30]:30s} cost=${cst:>7.4f} lines={lines:>8d} lines_per_dollar={lpd:>.0f}') else: print(f'{name[:30]:30s} cost=$0 (free) lines={lines:>8d}')回滚行为
cur.execute("SELECT id, title, revert FROM session WHERE revert IS NOT NULL AND revert != ''")reverts = cur.fetchall()print(f'sessions_with_revert={len(reverts)}')cur.execute("SELECT COUNT(*) FROM session WHERE revert IS NULL OR revert = ''")nr = cur.fetchone()[0]print(f'sessions_without_revert={nr}')项目-Agent 交叉分析
cur.execute(""" SELECT COALESCE(p.name, p.worktree, '(unknown)') as pname, s.agent, COUNT(s.id) as sc, AVG((SELECT COUNT(*) FROM message m WHERE m.session_id=s.id AND json_extract(m.data, '$.role')='user')) as avg_um FROM session s LEFT JOIN project p ON s.project_id = p.id GROUP BY s.project_id, s.agent ORDER BY pname, sc DESC""")for pname, agent, sc, avg_um in cur.fetchall(): print(f'{pname[:25]:25s} | {str(agent or "unknown"):15s} | sessions={sc:>2d} | avg_um={avg_um:.1f}')
conn.close()图表绘制
import matplotlibmatplotlib.use('Agg')import matplotlib.pyplot as pltimport numpy as np
# 图 1:小时分布柱状图(数据见时间节律代码输出)hours = list(range(24))counts = [119,36,0,0,0,0,0,0,0,0,0,0,6,25,52,40,43,78,61,29,61,47,57,138]colors = ['#1a1a2e' if h<12 else '#16213e' if h<17 else '#0f3460' if h<22 else '#e94560' for h in hours]fig, ax = plt.subplots(figsize=(12, 5))ax.bar(hours, counts, color=colors, edgecolor='white', linewidth=0.3)ax.set_xlabel('Hour of Day (UTC+8)', fontsize=11)ax.set_ylabel('User Messages', fontsize=11)ax.set_title('User Message Distribution by Hour', fontsize=13, fontweight='bold')ax.set_xticks(hours)ax.set_xticklabels([f'{h:02d}:00' for h in hours], rotation=45, fontsize=8)for h, c in zip(hours, counts): if c > 0: ax.text(h, c+2, str(c), ha='center', fontsize=7, fontweight='bold')ax.set_ylim(0, max(counts)*1.15)ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)plt.tight_layout()plt.savefig('chart_hourly.png', dpi=150)
# 图 2:Prompt 趋势(均值 + 中位数,数据见 Prompt 长度演化代码输出)days = ['05-08','05-09','05-10','05-11','05-12','05-13','05-14', '05-15','05-16','05-17','05-18','05-19','05-20','05-21','05-22']means = [50,703,229,272,152,331,253,101,57,61,38,188,67,474,64]medians = [31,54,28,22,22,37,33,22,34,38,23,188,25,309,58]ns = [7,36,100,33,18,112,162,92,146,52,4,2,9,7,12]
fig, ax1 = plt.subplots(figsize=(14, 5))x = range(len(days))ax1.bar(x, ns, alpha=0.12, color='gray')ax1.set_ylabel('Message Count', fontsize=10, color='gray')ax1.tick_params(axis='y', labelcolor='gray')ax2 = ax1.twinx()ax2.plot(x, means, 'o-', color='#e94560', linewidth=2, markersize=6, label='Mean length')ax2.plot(x, medians, 's--', color='#0f3460', linewidth=2, markersize=6, label='Median length')ax2.set_ylabel('Prompt Length (chars)', fontsize=11)ax2.set_ylim(0, max(means)*1.2)ax2.fill_between(x, means, medians, alpha=0.06, color='#e94560')ax1.set_xticks(x)ax1.set_xticklabels(days, rotation=45, fontsize=8)ax1.set_title('Prompt Length Evolution (Mean & Median per Day)', fontsize=13, fontweight='bold')ax2.legend(loc='upper right', fontsize=9)ax1.spines['top'].set_visible(False)plt.tight_layout()plt.savefig('chart_prompt_trend.png', dpi=150)
# 图 3:Agent 分层交互节奏(数据见交互节奏代码输出)agents = ['karpathy-build', 'plan', 'unknown', 'build']medians_ag = [126, 97, 155, 183]means_ag = [224, 164, 327, 215]ns_ag = [393, 164, 137, 17]fig, ax = plt.subplots(figsize=(10, 5))xi = np.arange(len(agents))w = 0.35ax.bar(xi-w/2, medians_ag, w, color='#e94560', edgecolor='white', label='Median gap (s)')ax.bar(xi+w/2, means_ag, w, color='#0f3460', edgecolor='white', label='Mean gap (s)')ax.set_xticks(xi)ax.set_xticklabels([f'{a}\n(n={n})' for a,n in zip(agents,ns_ag)], fontsize=9)ax.set_ylabel('Seconds', fontsize=11)ax.set_title('Interaction Pacing by Agent', fontsize=13, fontweight='bold')ax.legend(fontsize=9)ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)plt.tight_layout()plt.savefig('chart_pacing.png', dpi=150)
# 图 4:成本效率散点图(数据见成本效率代码输出)projects = ['Chestnut-Astro', 'Infernux', 'Name-Picker', 'Chestnut-Studio']costs = [18.68, 1.27, 0.24, 0.23]lines = [15058, 0, 6068, 12083]lpd = [806, 0, 24845, 52152]fig, ax = plt.subplots(figsize=(10, 6))ax.scatter(costs, lines, s=[max(80,l*0.003) for l in lines], c=['#e94560','#0f3460','#16213e','#1a1a2e'], alpha=0.8, edgecolors='white', linewidth=1.5)for i,(p,c,l,e) in enumerate(zip(projects,costs,lines,lpd)): ox = 30 if i%2==0 else -30 oy = 10 if i<2 else -10 ax.annotate(f'{p}\n${c:.2f} | {l:,} lines\n{e:,} lines/$', (c,l), textcoords='offset points', xytext=(ox,oy), fontsize=8, ha='center', bbox=dict(boxstyle='round,pad=0.3', fc='white', alpha=0.85))ax.set_xlabel('Total Cost (USD, estimated)', fontsize=11)ax.set_ylabel('Lines Changed', fontsize=11)ax.set_title('Cost Efficiency by Project', fontsize=13, fontweight='bold')ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)ax.set_xlim(-1, max(costs)*1.3)ax.set_ylim(-500, max(lines)*1.2)plt.tight_layout()plt.savefig('chart_cost.png', dpi=150)附录 B:数据溯源与复现
以下对照表列出了正文中各数据来源与其对应的附录代码节,以确保全文所有数字可被独立验证:
| 正文章节 | 数据内容 | 对应附录代码节 |
|---|---|---|
| 总体指标 | 核心指标表 | 总体指标与会话列表 |
| 时间节律 | 小时分布、星期分布、自然日分布 | 时间节律 |
| 会话结构 | 交互深度分布、高迭代会话、持续时间 | 总体指标(每会话详情循环) |
| Prompt 长度 | 日均均值/中位数/P90 | Prompt 长度演化 |
| 交互节奏 | 整体间隔分布 + Agent 分层 | 交互节奏 |
| Agent/模型 | Agent 分布、花费、项目花费 | Agent 与模型偏好 |
| 工具使用 | 工具频次表 | 工具使用 |
| 代码产出 | 25 行 patch 表、相关性、TODO | 代码产出与相关性检验 |
| 成本效率 | 项目花费、行/美元 | 成本效率 |
| 回滚行为 | revert 字段查询 | 回滚行为 |
| 项目-Agent | 交叉分析表 | 项目-Agent 交叉分析 |
| 图表 | 4 张分析图 | 图表绘制 |
复现条件:Python ≥ 3.10(statistics.correlation 需 3.10+),matplotlib ≥ 3.5,numpy ≥ 1.21。数据库路径需替换为实际的 opencode.db 位置。由于数据库存储的是个人使用记录,读者在使用自身数据库复现时将得到不同的数值,但代码逻辑和统计方法完全一致。